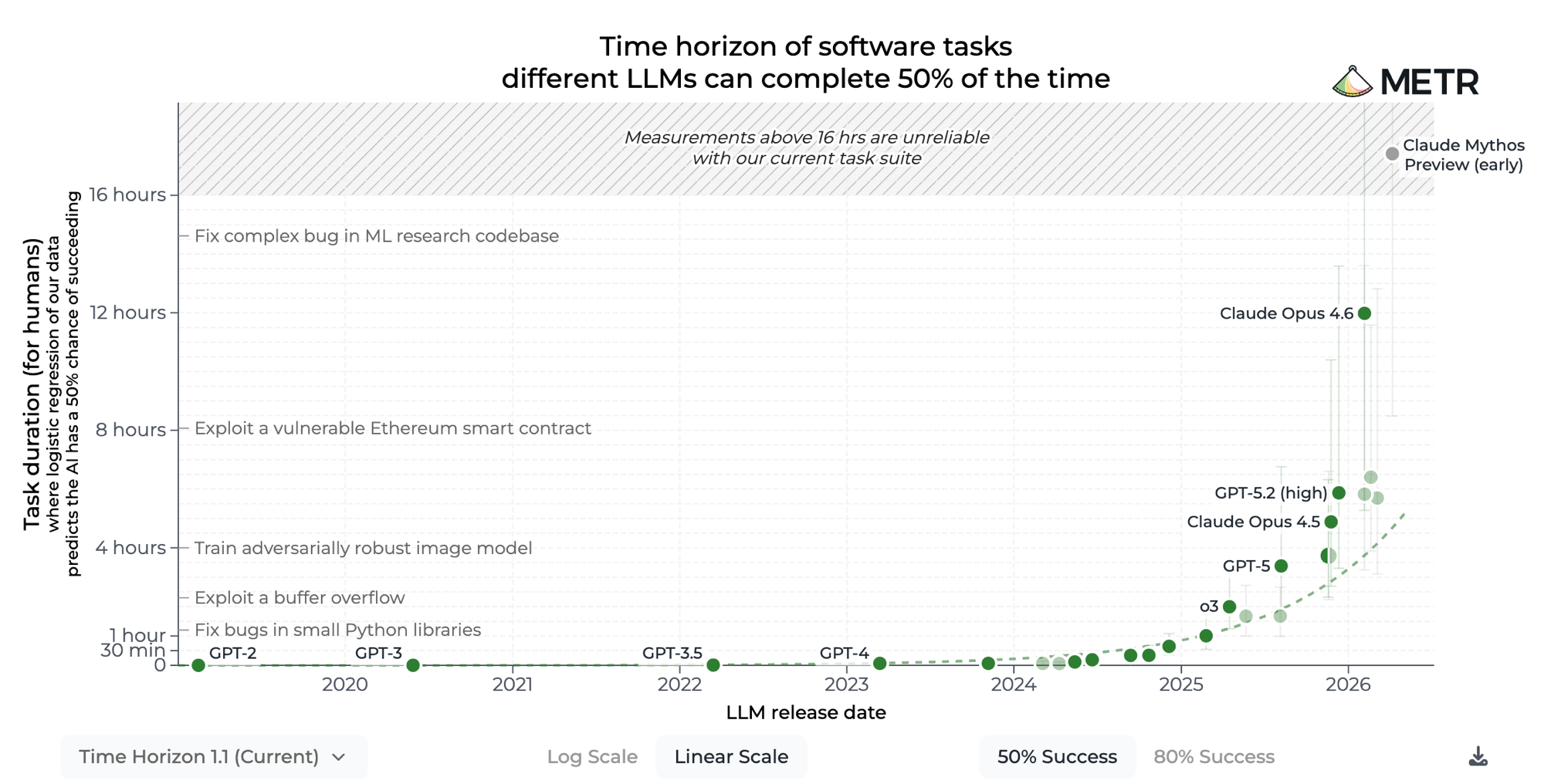
Tasks scale quadratically
Models now run eight-plus hours and finish the job. What task do you have that runs longer than a few minutes?
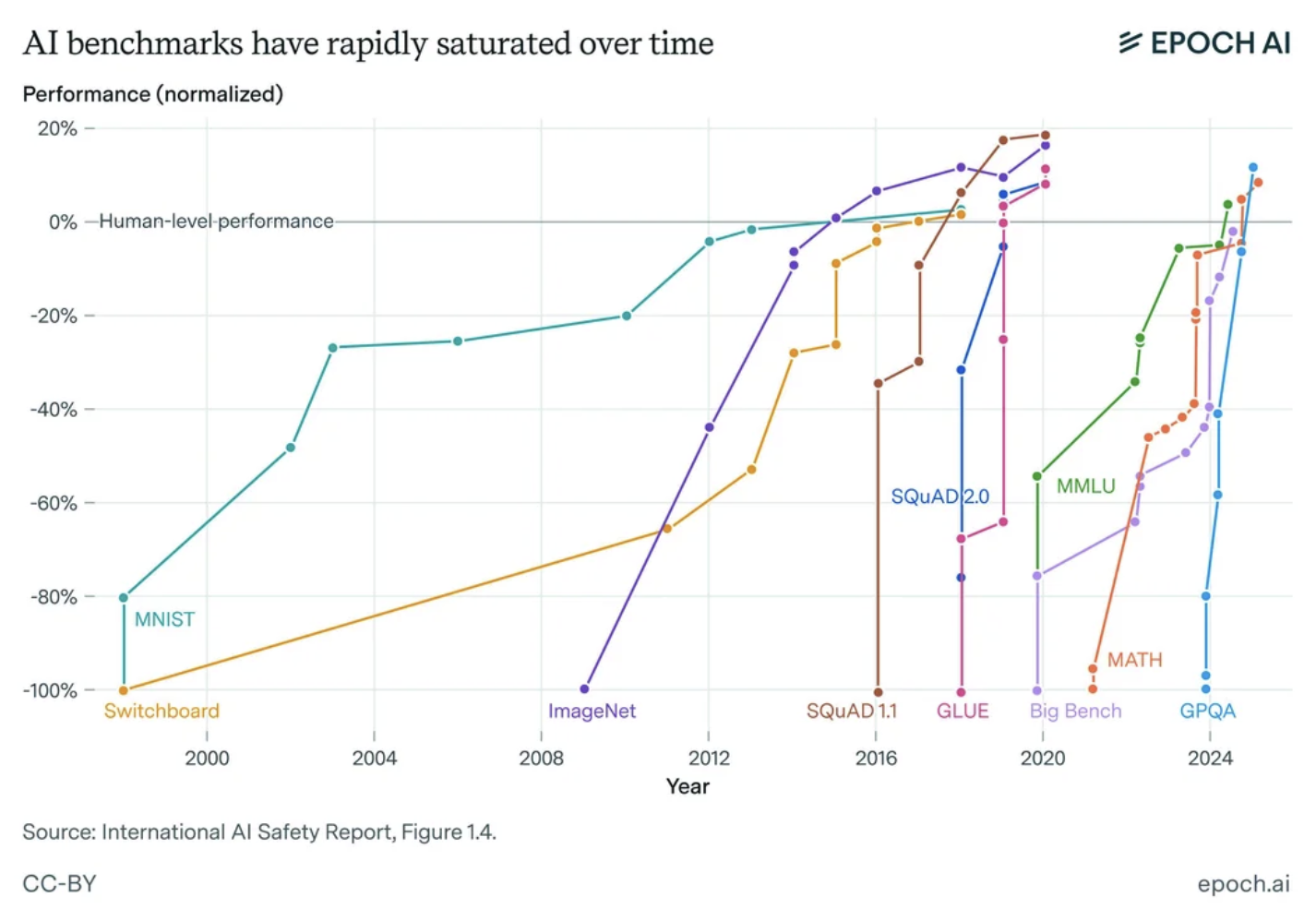
Benchmarks fall within hours
The moment a benchmark is published, it's beaten. The real question isn't whether AI can solve it. It's which benchmark you want AI to solve.
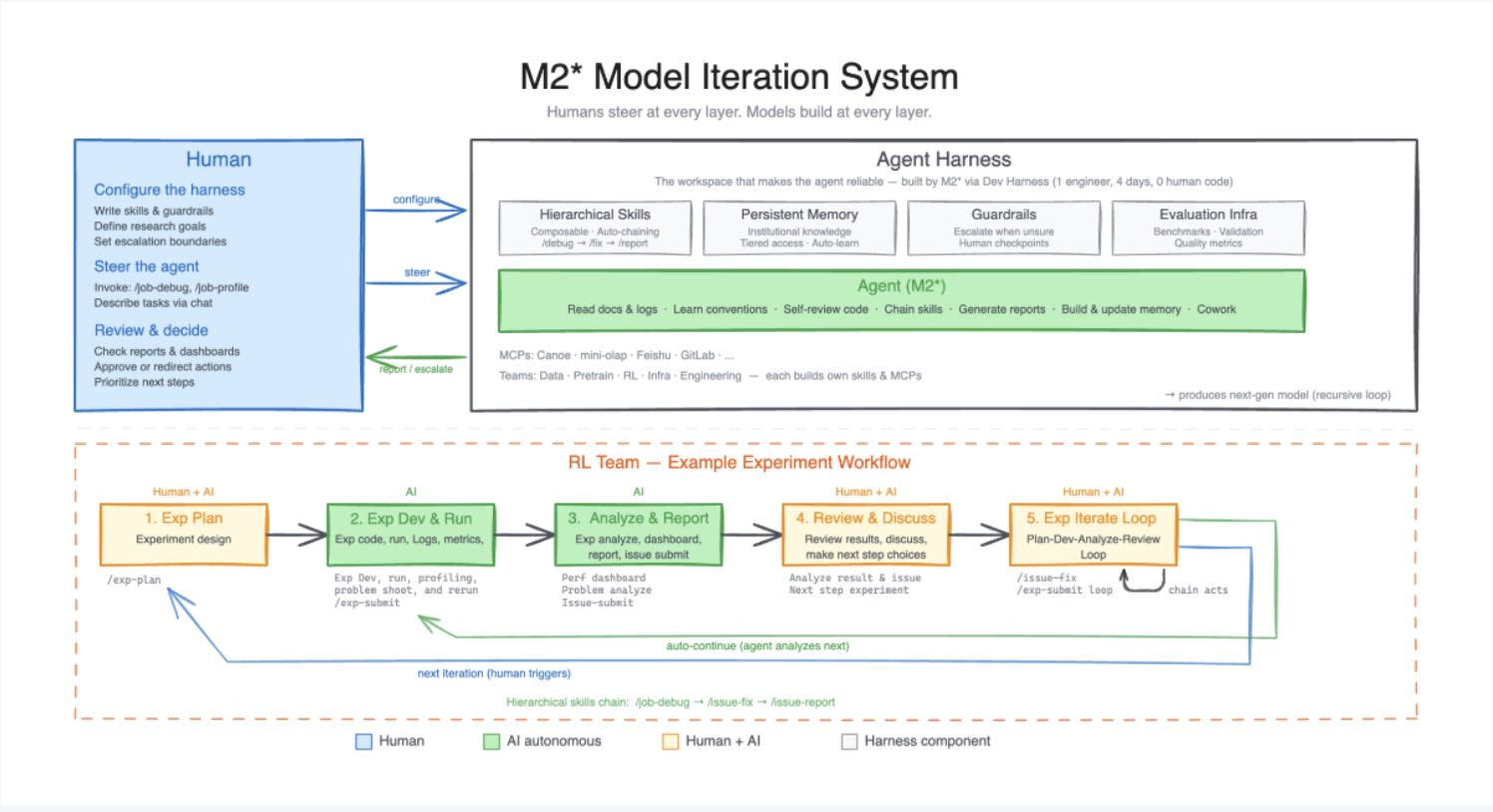
Your company is a data generator
Humans steer at every layer; models build at every layer. Agents generate data, the data trains the model, and a better model runs a better company. A recursive loop.
Claude ships every single day
Their pipeline is streamlined for AI. They embrace it instead of fighting it. Things break, they fix fast, and the cost of failing is almost nothing.
Source: The Product Compass. Anthropic releases, Feb–Mar 2026.

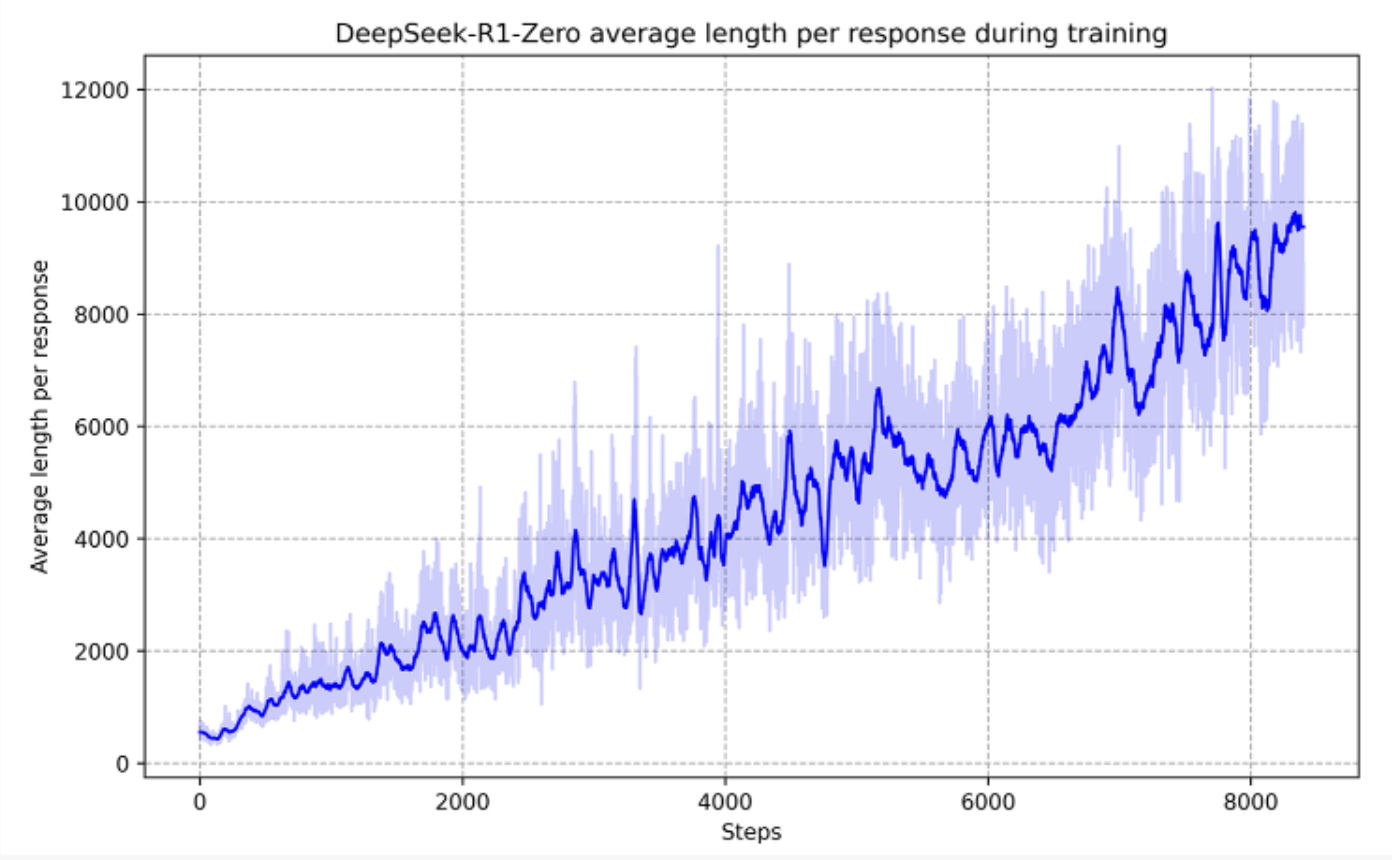
Just keep nudging
Tiny nudges, big gains. The same loop that taught DeepSeek-R1 to keep thinking longer all on its own.
Auto-research while you sleep
Give AI an objective, not a task, plus tight guardrails: a 5-min experiment, revert-if-worse, keep-if-better. It runs for hours; you wake to a result better than weeks of your own work.
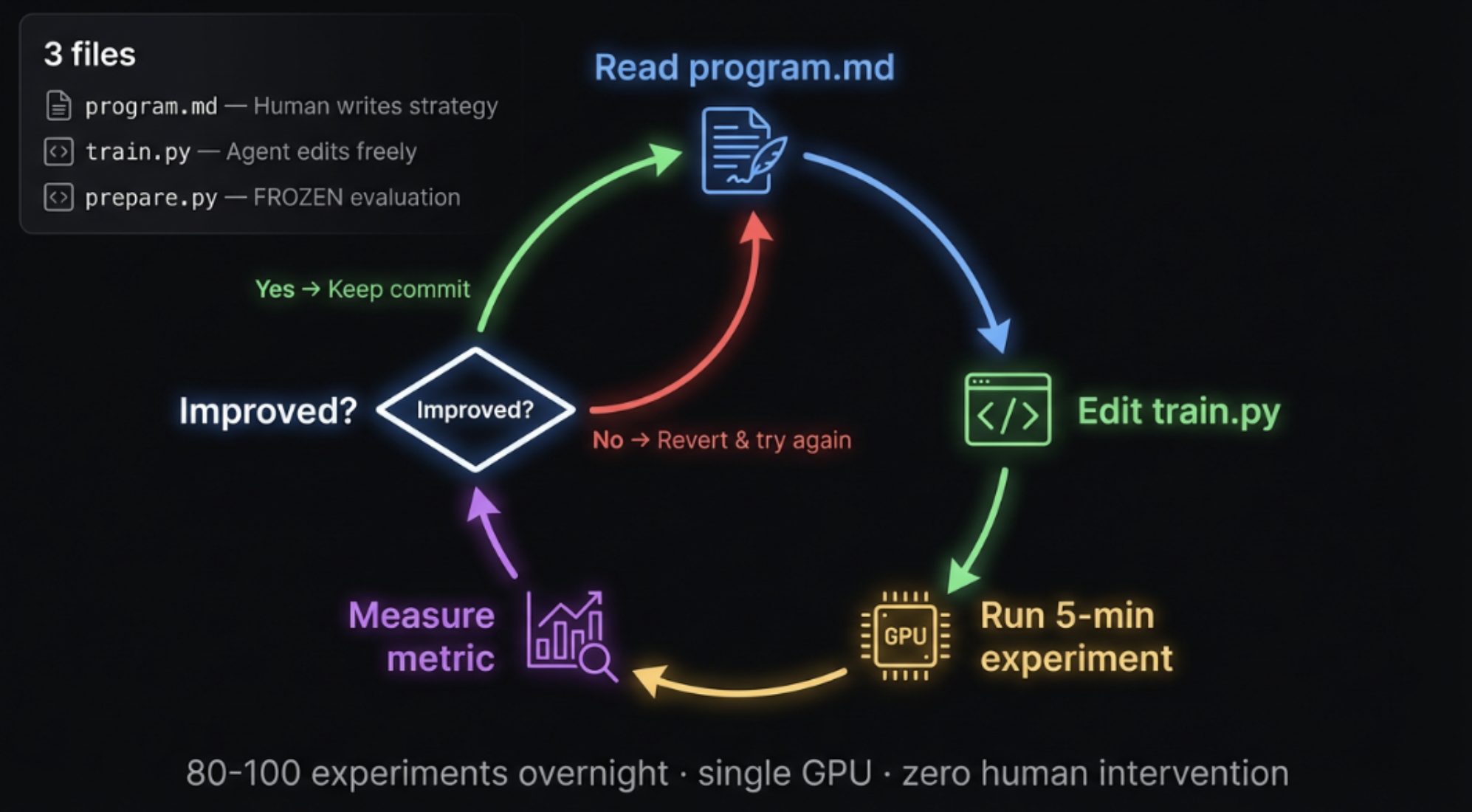
How the loop works
Three files, one cycle: a human writes the strategy in program.md, the agent edits train.py, runs a 5-min experiment, measures, and keeps the commit only if it improved. 80–100 times a night, zero intervention.
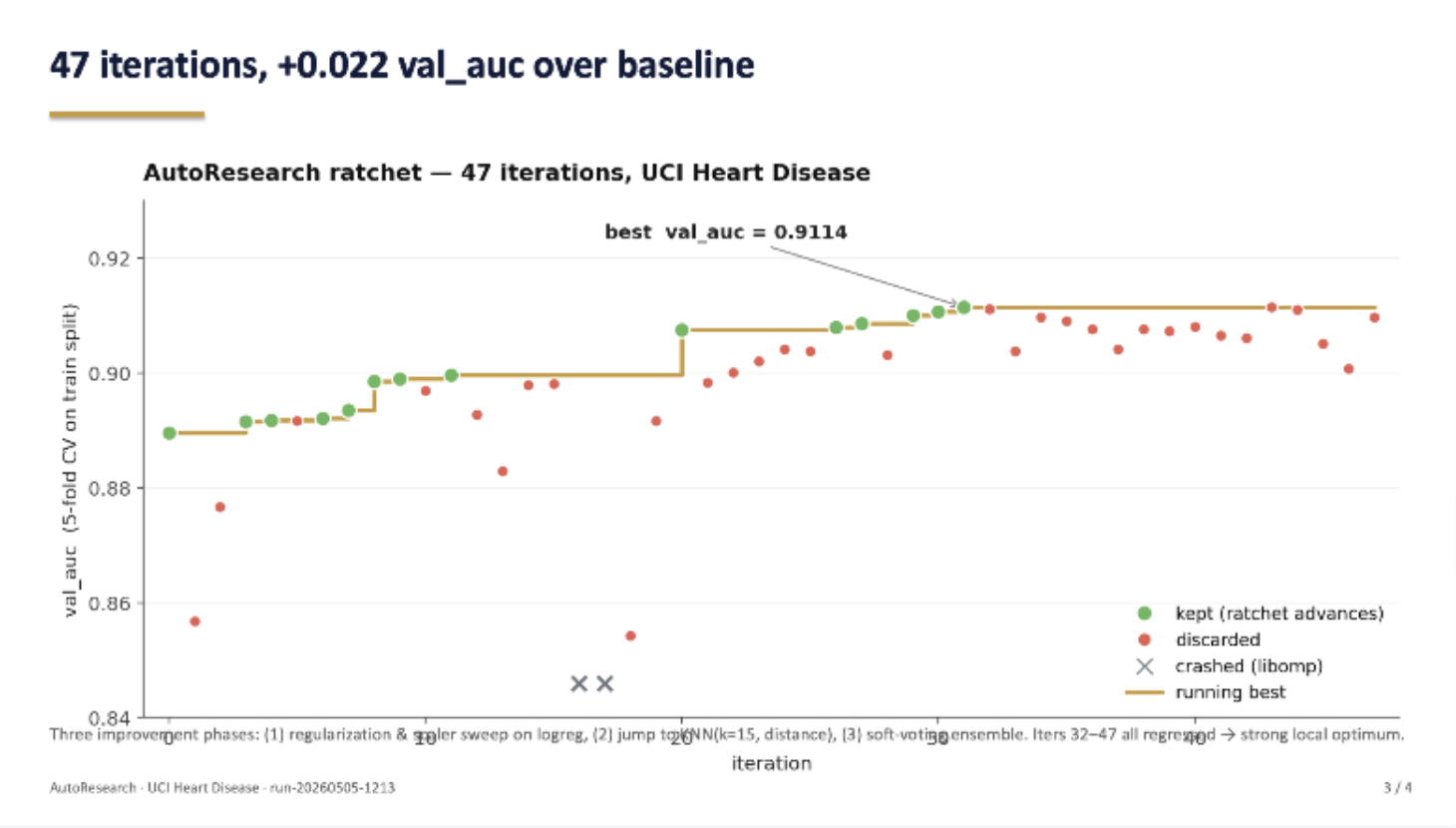
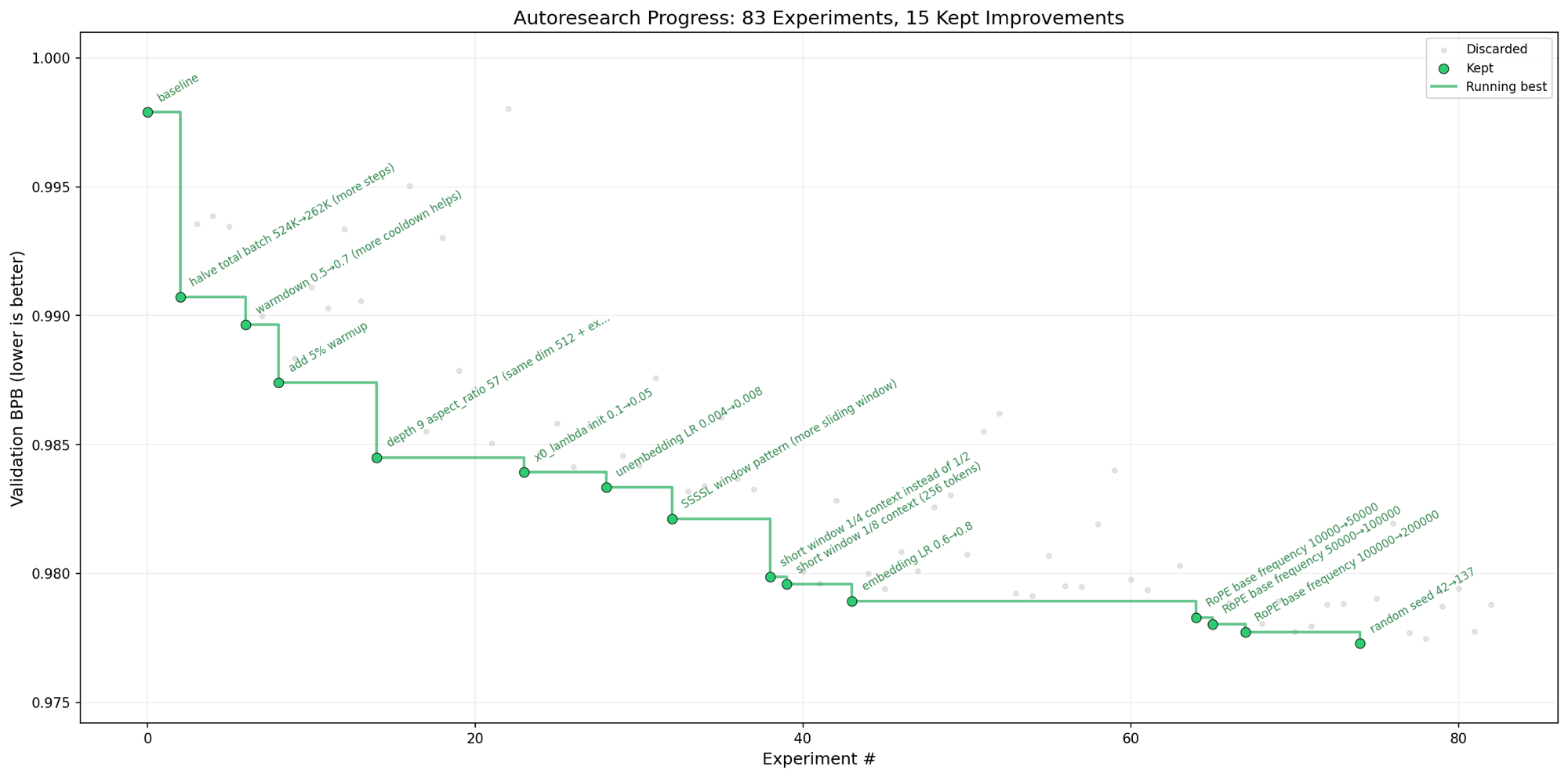
47 iterations, +0.022 val_auc
Run on the UCI Heart Disease set: 47 iterations, keep-if-better. val_auc ratchets from 0.889 to 0.9114, then plateaus at a strong local optimum.
AutoResearch · UCI Heart Disease · run-20260505-1213