The bottleneck
is us.
AI already works for hours, unsupervised, and gets the job done. The limit is how ready we are to use it, not the model.
Today's menu
- Slow start
- Learn with files
- Teach yourself and the AI
- MCPs and data
- Loops and self-improvement
It already runs for eight-plus hours
Unsupervised, and it finishes the job. Most tasks fit within that window.
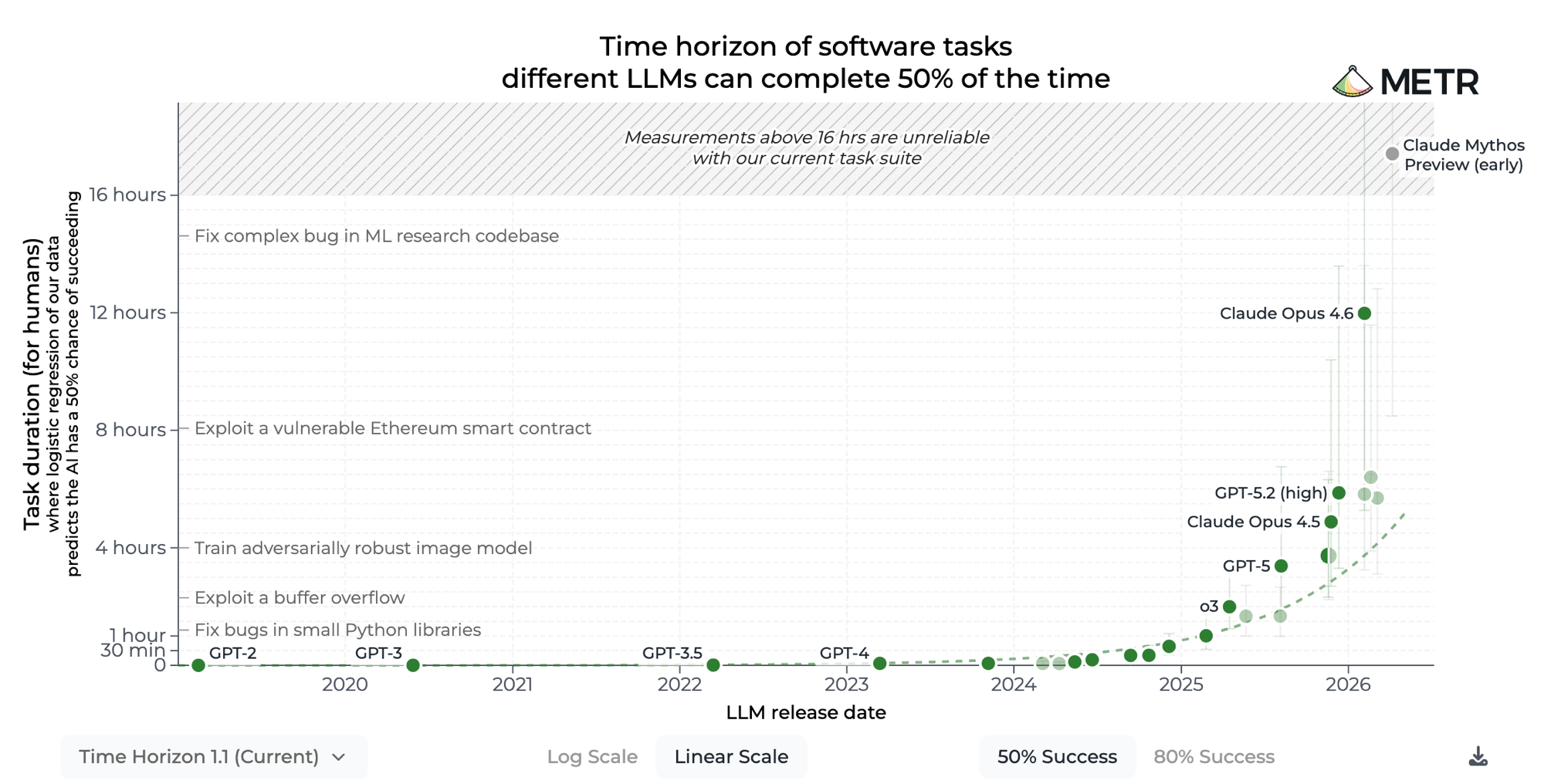
The proof: Claude ships every single day
Anthropic runs AI throughout its own engineering pipeline. The technology is ready to use.
Source: The Product Compass. Anthropic releases, Feb–Mar 2026.

So, what is Toqan?
An LLM / agent with access to an entire virtual computer, via the command line. That's why it can stay always on, why we can manage it, and why it's easy to connect securely.
A live walkthrough
of Toqan
See it all in motion. Then we get into the how.
Open the tour: DashboardQuality depends on your specs, not the model
Ask for "a snake game" and you get one. Add music, sound, a scoreboard, a blue theme, confetti on every point and it's far better. You specified what "correct" means.
Try it: paste this
No setup, no boilerplate, one plain sentence. Copy it into your agent and a working, hosted app appears.
Try again with improved specifications
Same game. Now you define what "good" means, and the model follows every word.
Chat, files & sending files
Downloading a person.md, uploading it back into the chat, attaching a doc for it to read. See the file flow in Toqan before we put it to work.
Open the tour: Chat & filesAdd your voice and design
AI output defaults to generic because nothing tells it otherwise. Add your voice and design, and it stops looking generic.
Or start from a person.md
Fifteen ready-made voice profiles, one per Prosus board member, scraped from the public web. Pick one and click to download.
Inside fabricio-bloisi/person.md
One file, and the agent already knows how to sound like him: tone, vocabulary, structure, even the guardrails.
Tone & persona
Optimistic, forward-looking, ambitious. Inspiring, energetic, authoritative, direct — a visionary tone that pushes bold aspirations and rapid execution.
Vocabulary
Action-oriented words like "abundant," "moat," "discipline," "compounds," plus tech/business terms: "AI native," "ecosystem," "high-growth startups."
Structure
Opens with a personal anecdote or bold statement, builds a clear argument, closes with a call to action or a visionary outlook.
Drafting guardrail
Drafts must be fact-checked and approved before publication — never invent experiences, quotations, or implied endorsements.
Save it as data/person.md
Drop the file you just downloaded into your agent's data folder, and any prompt below can write in that voice.
Create a design.md
Point an agent at a site you love. It reads the look and saves a design.md any agent can reuse.
Skills & the Skill Market
Where skills live, how to browse the market, and how to install one in a click. Then we install board-bio together.
Open the tour: SkillsInstall this skill
One skill, board-bio, generates and deploys a polished personal bio site to <name>.prosusboard.com in one go. Install it before the next step.
Turn person.md into a bio page
The board-bio skill takes it from here: your person.md becomes a live, on-brand bio site.
Teach AI your business
A handful of markdown files give an agent the context a new hire would need: who's who, what matters, how you win. Drop in people.md, okr.md, strategy.md, and every task lands in context.
One voice. Every artifact.
Turn your voice and design into agent-readable files. They carry from task to task — the same identity behind your decks, emails, and apps.
Show off your bio site
Pull up the page board-bio just deployed for you. Share the link, and let's see a few live in the room.
Learning, personalized
Tell AI who's reading, their role and their background, and one idea becomes two explanations. The same concept, reframed for an exec and an engineer, each in their own vocabulary.
Explain me skills
Before you build one, let AI explain how skills work — reframed for you, using your own background and voice.
One topic, two readers
The same skills, read two ways. The MBA gets the business case. The engineer gets the implementation.
A skill is a standard operating procedure your agent never forgets
You document the process once — the way you'd write an SOP for a new analyst — and the agent executes it the same way every time, forever. No onboarding, no drift — the knowledge is captured once and reused every time.
Reusable instructions, loaded on demand
A skill is a markdown file with YAML frontmatter (name + trigger description) and a body of step-by-step instructions. The agent matches the request against the trigger, and if it fires, injects the file's contents into context at that turn — a lazily-loaded, dynamically-dispatched system prompt fragment. No fine-tuning, no embeddings, no retrieval pipeline: just conditional context injection, versioned as a file in your repo.
When to use skills
Notice yourself correcting your agent twice, or a process nobody's written down that you need done reliably. That's the signal: capture it once, as a skill, and stop repeating the correction.
Automate your first skill
Capture it once and never prompt it again. Every mail already sounds like you.
Learning to make videos is just installing a skill
Install hyperframes-animation once to turn a long write-up into a 30-second video. Your voice and metaphors carry into the visuals too.
Take a break.
Grab a coffee, stretch, reset. We pick up right after.
Setting up an MCP server
Under Connections: one-click connectors for Slack, Notion, Linear, Google Workspace, and more — or wire up any custom endpoint yourself.
Open the tour: MCP setupConnect your data
MCP servers live under Connections. Getting access to data was never this easy, agents can act across them directly.
Or bring your own server
Copy paste the values of the shared HTML
Confirm the source is trusted, and that it won't expose easily prompt-injected systems like email or calendar.
Prompt to test
Connect one MCP server from Connections — a built-in one like Notion or Linear is fastest — then ask your agent to actually use it.
Turn it into a chart
Ask for the analysis and the visual in one go — segment, sign-flip, and chart the trajectory.
Density beats volume
AI made content cheap to produce, but reader attention didn't grow. Don't ship 80 pages — make it dense, lead with hierarchy, and people will actually give feedback.
Cut it to one page
Turn a long report into a single dense HTML page that earns feedback.
Stop steering.
Let it learn.
Give AI a goal and let it research, build, and improve on its own — through repeated trial, measurement, and revision.
Just keep nudging
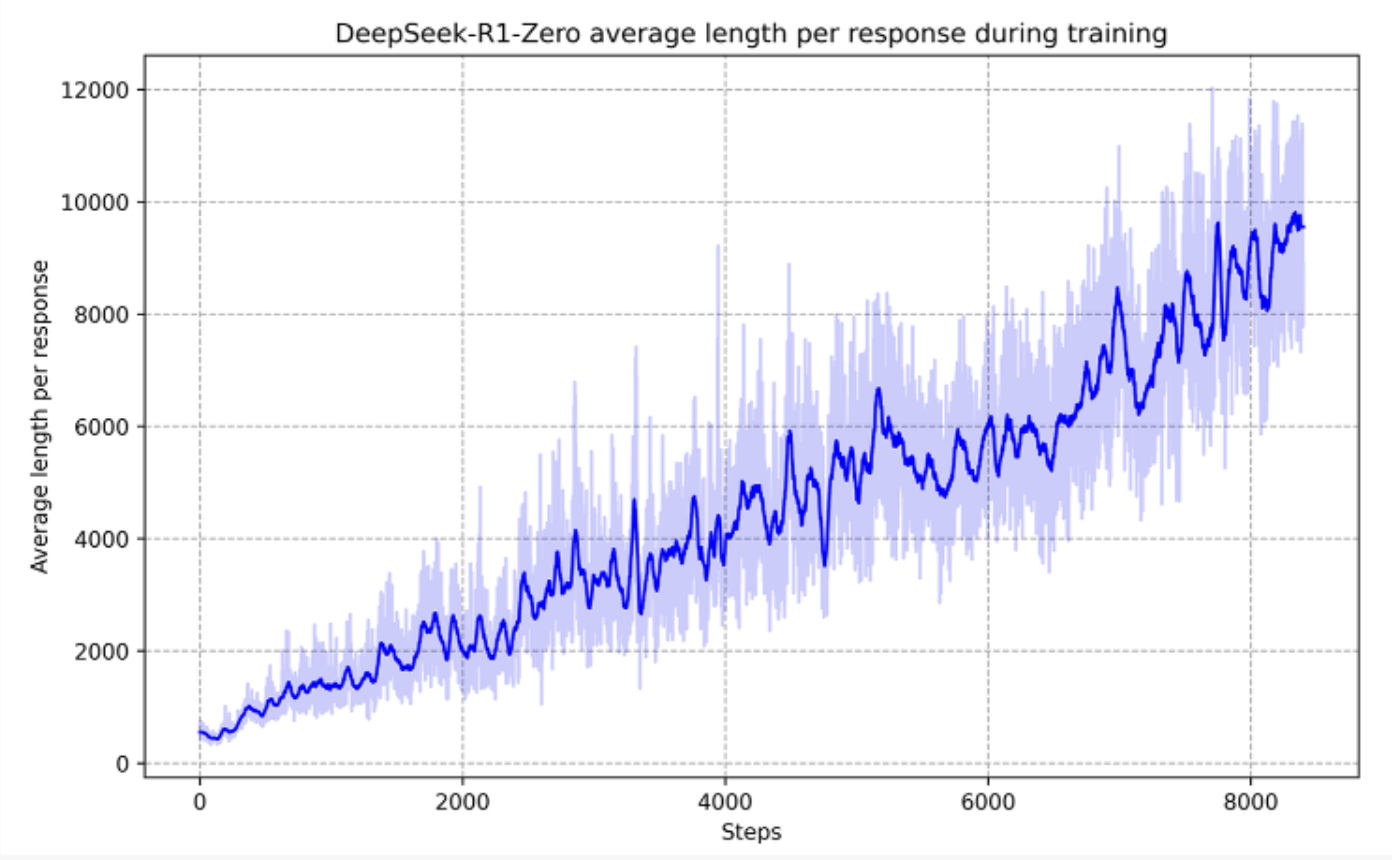
Small, repeated nudges compound. This is the same loop that taught DeepSeek-R1 to keep thinking longer on its own.
Your turn: research it
Point it at a real question and let it run. We'll sharpen the technique on the next slides.
Don't one-shot the search
The agent won't nail the query on the first try — the web is too vast. Loop it instead: search, evaluate the source, find the gaps, dig deeper or adjust. A depth-first beam search.
Loop the search
One living report, five passes. It finds its own gaps and digs deeper.
Let it loop and review
Give it a goal and let it loop: create, review, revise, repeat. A model rarely catches its own faults while generating. But force it to review, again and again, and quality climbs with every pass.
Run the restaurant
Your agent runs the bistro and learns the business, day by day.
We gave AI a restaurant
A simulated 22-table Rotterdam bistro, 30 days, one goal: end the month in profit. No instructions. Every morning it reads yesterday's numbers, adjusts staffing, stock and prices, and learns from what happened.
REST-bench · calibrated to real restaurant-industry research
The simulations
REST-bench models a real market and a strict scorer, so the agent's every move has consequences.
A simulated market
REST-bench · prosus.md/exercises/exercise-6 · live dashboard at localhost:8765
Profit, but not at any cost
REST-bench · The Rotterdam Table · 22 tables · 78 seats · €10,000 starting capital
The score comes with a reflection
Along with the score, the agent explains which strategies worked, where it lost money, and what it would try next — input for the next run.
Reset — and run it better
You've seen one month play out. Reset the run, then brief your agent on what to change.
Kick off another task with instructions you think will improve this run
Go around the room
Compare your second run with your first. What instruction moved the score most? What surprised you?
Can we do EVEN better?
Let's evaluate our strategy one more time and try to reach higher.
Reset — round two
You now have two months of evidence. Compare the runs, keep what worked, fix what didn't.
Look at both previous runs, compare what worked and what didn't, and kick off another task with instructions that improve on this run
What can your loop teach you?
It runs hundreds of experiments you wouldn't try by hand, and the winning strategies are often counter-intuitive. You set the goals, taste, and guardrails; it returns strategies you hadn't considered.
Could AI run your loop?
Three tests: the outcome is measurable, you can iterate fast, and the goal is clear. Pass all three and AI can learn to run that part of the business — ads, pricing, even org design.
From restaurant to company
If AI can learn to run a bistro in 30 days, what's the ceiling on more complex operations? This is the open question we're chasing next; the benchmark is public.
github.com/collinear-ai/yc-bench ↗Knowledge sharing across portfolio was never this effective
A loop running at one company surfaces strategies that transfer. Point a second company's loop at the same learnings and it skips the trial-and-error the first one paid for.
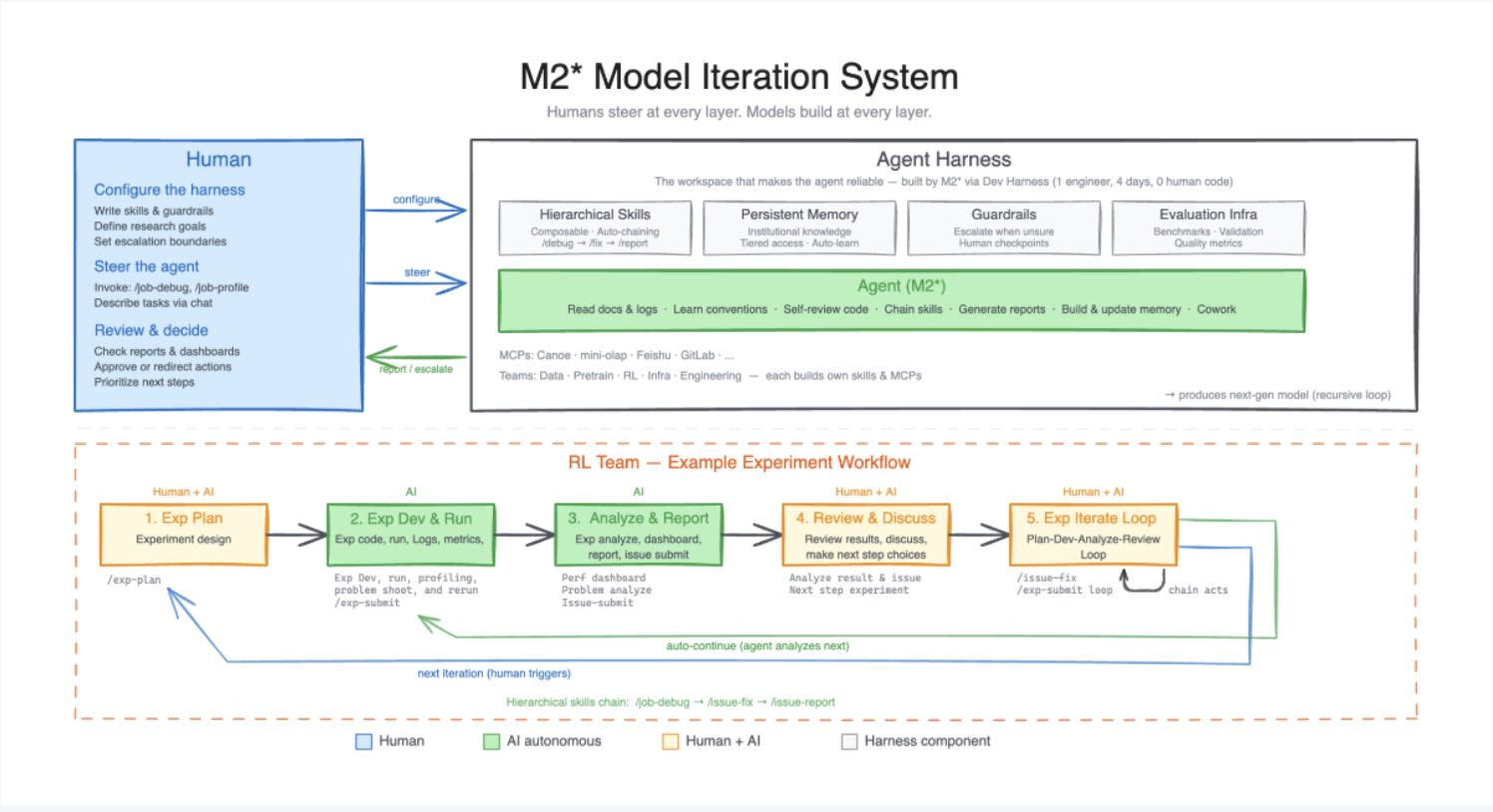
Your company is a data generator
Humans steer at every layer; models build at every layer. Agents generate data, the data trains the model, and a better model runs a better company. A recursive loop.
Verification is the new bottleneck
As generation gets nearly free, verifying what's actually right becomes the constraint. Prosus's edge: a billion customers, a verification layer at a scale almost no one else can match.
Four moves. One direction.
Each step increases what AI can do for us.
Make the business readable
Turn processes, goals, and knowledge into structured text. Documentation becomes the fuel.
Turn learnings into assets
Share context, skills, and blueprints across teams and portfolio companies. No gatekeeping.
Align your goals and metrics
If you set goals, make sure you have the correct metrics to follow them. Think sensitive, correlated metrics.
Aim for full autonomy
The north star. Not today's reality, but every step pushes us closer: AI loops that learn, research and build on top of structured context, at machine speed.
Thank you.
The bottleneck was never the model. Go build.